Dimanche 25 octobre 2020
Vers un CI à 100%, ou comment régler les problèmes du quotidien
By Cedric !
Vers un CI à 100%, ou comment régler les problèmes du quotidien.
Toute personne ayant travaillé au développement d’un logiciel peut le dire : le cycle de développement d’un logiciel est loin d’être un fleuve tranquille.

De la récupération des besoins des clients à la mise en production en passant par l'implémentation, chaque étape apporte son lot de soucis et chaque année apporte son lot de nouvelles techniques, méthodologies et outils. Cela permet de simplifier nos vies jusqu’à une automatisation totale chacune de ces étapes.
Pourquoi il y a encore autant de tâches manuelles? Pourquoi la création d’une release prend autant de temps? Pourquoi est-ce que l’équipe est incapable de produire une nouvelle version chaque semaine?
Chaque situation ayant sa spécificité, à chaque fois les mêmes excuses sortent de la bouche des développeurs et responsables : le manque cruel de temps!
A cette remarque, il n’y a qu’une seule réponse possible : prenez-le!
Le temps gagné à streamliner chacun des process et améliorer la vie des développeurs jusqu’au QA allège le fardeau de tout le monde et fait toujours gagner du temps sur le long terme.
Cependant, chez toutes les équipes que j’ai pu croiser, j’ai toujours constaté la volonté d’améliorer la situation. Je pense ainsi que le problème n’est pas abordé sous le bon angle. Je veux donc ici, non pas faire une roadmap, mais un recueil de tous les problèmes du quotidien, proposer une éventuelle solution et une estimation de temps de mise en place.
Je vais considérer que pour votre projet, vous utilisez déjà GIT et que vous savez mettre en place une usine de build.
Problème 1: on a pas de spec ni de doc!
La source de l’arrachement des cheveux dans une équipe.
Certaines activités sont d’une facilité déconcertante, surtout pour des personnes qualifiées et les membres connaissant l’application sur le bout des doigts. Mais il ne faut pas oublier que le turnover fait partie des plus grands risques qu’une équipe peut connaître. Perdre les développeurs les plus aguerris est une plaie, et devoir former des juniors est un gouffre de temps.
Alors pourquoi ne pas se faciliter la vie ? Prenez le temps avant et après chaque tâche de mettre à jour un ensemble de documents précisant l’ensemble des fonctionnalitées et leur organisation technique. Les dessins sont très appréciés, les schémas sont la base de toute bonne compréhension.
Je vous propose de faire ces schémas avec https://plantuml.com (Open source, nécessite java) ou que vous pouvez même tester en ligne avec https://www.planttext.com.
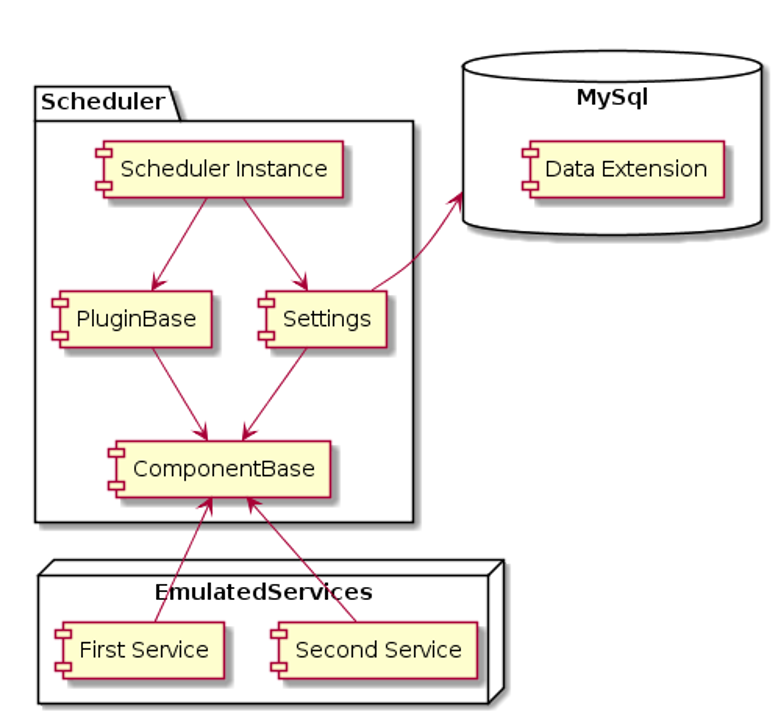
Pourquoi ce format ? Parce qu’il s’accorde très bien avec la gestion de source de GIT. Une description textuelle de votre architecture, des blocs à relier avec des petits traits. Très simple et efficace. N’hésitez pas à faire plusieurs schémas, découpez au maximum l’ensemble fonctionnel afin de faciliter la vie au cerveau des développeurs.
Combien de temps ça prend ? Soyons honnête, si vous n’avez absolument rien, comptez une bonne demi-journée pour lancer le travail. A chaque nouvelle grosse fonctionnalité il faut compter une demi-heure à prendre pour mettre à jour ou créer un nouveau fichier.
Mettez ces schémas accessible directement dans le README en racine de votre dépôt et profitez d’une clarté de lecture inégalée pour toute nouvelle personne arrivant sur le projet.
Le fait de poser les crayons, sortir de la tête du guidon et prendre du recul sur une tâche complexe qui nécessite plusieurs itérations va remettre une gros coup de clarté et redéfinir vos objectifs.
Problème 2: le code review est trop long
Ceci est pour moi l’une des plus gros source de frustration. Il n’est arrivé d’avoir des retours sur une PR plus d’une semaine après avoir proposé mon code. En attendant, je suis bien obligé d’aller sur d’autres sujet.
Changer d'environnement et reprendre le code peut prendre près d’une demi-heure dans de nombreux cas:
- Sauvegarder le travail courant,
- Reprendre la branche en question
- Faire une modification,
- Compiler
- Se remettre sur l'environnement de test en question.
- Tester
- Faire son commit et pusher
- Revenir sur le travail qu’on a mis en pause et refaire toutes ces étapes.
Un enfer !
Qu’est-ce qui ne va pas alors ? Il y a de nombreuses raisons:
- L’indisponibilité du reviewer référent
- La divergence des avis des reviewers
- La lecture du code est trop longue car trop de modifications
Ne pas oublier d’ajouter des beautifiers de code pour chaque langage utilisé (2h par prettifier) pour simplifier la lecture.
Si le référent technique souhaite voir une approche privilégiée, il faut que celle-ci soit donnée AVANT le développement, et non après. Rien de plus frustrant que d’entendre: “J’aurais préféré que ça soit fait autrement” après avoir passé plusieurs jours à implémenter...
Il faut faire confiance à l’équipe, il n’y a pas qu’une seule solution. Pour rappel, quelques bonnes pratiques et conseils lors d’une code review:
https://medium.com/palantir/code-review-best-practices-19e02780015f
http://www.bettercode.reviews/
S’il y a une guideline ou dès règles à suivre, ajoutez les dans des git-hooks. Le travail de rejet d’une PR mal travaillée doit se faire instantanément.
Problème 3: la BDD n’est pas disponible
Un problème récurrent dans le cycle de développement peut être l’accès à la base de données.
Les environnements de développement doivent tourner à minima avec une BDD par version déployée et active chez vos client, ainsi qu’une base de validation propre pour vos étapes de QA. Le concept consiste à vérifier le plus rapidement possible un éventuel problème pour apporter rapidement un correctif.
Cependant, une évolution applicative où plusieurs développeurs manipulent le schéma de la base est souvent dangereux :
- Deux développeurs manipulent des données qui interagissent entre-elles
- Une fonctionnalité n’est pas validée rapidement et la tâche suivante a une dépendance sur la première
- Un rollback est nécessaire dû à une erreur humaine.
Ici, il n’y a pas beaucoup de solutions. Il faut être capable de répliquer une base développement par développeur et par environnement. Par conséquent, l’investissement va être beaucoup plus lourd.
Le plus facile reste d’intégrer docker dans vos environnements (développement, build …) et bien sûr d’apprendre à utiliser Docker! Si ce n’est pas encore le cas...
Compter une journée de formation par développeur et une à deux journées pour intégrer tout ça dans votre CI.
Pour démarrer avec Docker sur Windows: https://docs.docker.com/docker-for-windows/
Exemple d’intégration Oracle sur une image docker windows https://www.oracle.com/technetwork/topics/dotnet/tech-info/oow18windowscontainers-5212844.pdf
N’oubliez pas de garder une base de données minimaliste afin de ne pas consommer trop de disque dur.
Problème 4: Pas de couverture de test = pas de confiance en la couverture de test ou les tests sont trop longs
Ici, on a un sujet qui touche tout le monde. Jamais personne n’est satisfait de ses tests unitaires:
- Ne pas faire de test à pour conséquence de devoir tout re-valider manuellement et retomber à chaque fois sur les même problématiques
- Lorsqu’on ne connaît pas sa couverture de tests, on a vite peur de ne pas être en mesure de d’exécuter les cas nominaux
- Les tests qui prennent trop de temps vont dissuader les développeurs de les lancer ; les lancer sur la machine de build va bloquer les ressources disponibles pour les autres développeurs.
- Maintenir les tests peuvent est souvent un énorme calvaire.
Mais alors, qu’est-ce qui ne va pas? Peut-être pensez-vous être dans un cas particulier? Et si je vous disais qu’il existe une réponse qui correspond à tout problème de développement?
Il s’agit d’un problème d’architecture (et même d’outillage encore une fois! ;) ).
Partons du constat final, l'exécution d’un plan de test est trop long.
En considérant que vos tests unitaires sont bien écrits (ne dépendent pas d’une base de donnée up and running par exemple), Il s’agit d’un problème de couplage. Un trop grand nombre d'éléments sont à tester pour une feature qui n’est pas supposé les affecter. Ici, 3 cas sont envisageables:
- Votre application est monolithique et devrait être découpée en plugins (je vous laisse chiffrer le coup, mais réfléchissez-y bien, il s’agit bien souvent de juste déplacer du code dans différents projets que vous pouvez charger dynamiquement)
- Votre application est testée à partir d’un même projet de test. Vos différentes sous-couches ne sont donc pas testées indépendamment.
- Vous avez une complexité algorithmique trop élevée (et que vous pourrez ou non simplifier)
L’exemple du C# est en général très parlant : on commence par développer un projet, on essaie de le découper en fonctionnalitées ou objets qui bougent peu. On met ces choses quasi immuables dans un projet .csproj à part que tous les futurs projets se mettent à référencer. L’idée ici est de sortir ce type de projet de votre solution et les mettre sur un cycle de CI à part. Pensez à lui ajouter son propre projet de test ! Une fois que vous êtes confiant sur votre projet, publiez les DLL sur votre propre serveur NuGet! https://docs.microsoft.com/en-us/nuget/hosting-packages/overview
Constatez maintenant le triple gain:
- Plus besoin de recompiler la DLL en question.
- Une mise à jour de la DLL par un collègue sera propagée sur tous les postes sans avoir besoin de se mettre à jour sur votre CVS
- Les tests ne seront exécutés qu’une seule fois, et non pas à chaque changement.
Et la cerise sur le gâteau: on peut désormais gérer la possibilitée d’avoir une gestion des versions indépendante pour déployer plus facilement chez vos clients en cas de pépin.
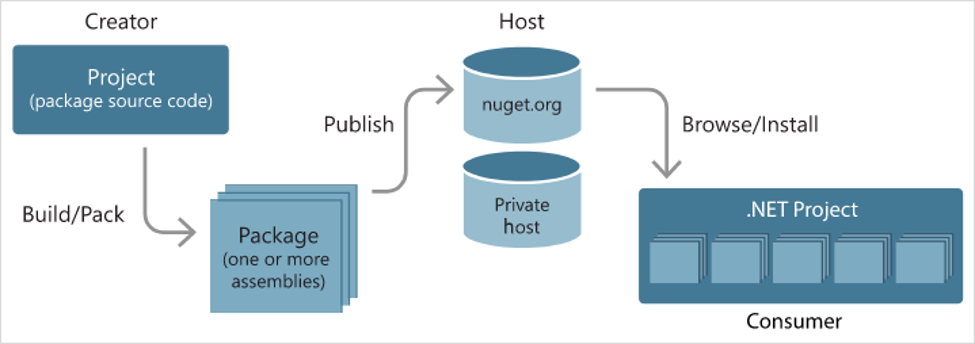
En quoi cela règle les autres problèmes? Si vous n’avez pas confiance en votre scope, vous pourrez plus facilement avoir un aperçu de la couverture de chaque couche applicative. Un conseil utile : annoter les classes de test pour connaître le scope attendu fonctionnel de couverture. Les commentaires sont un début, peut-être pourrez vous trouver une façon d’automatiser tout ça!
Et quand on a pas de test unitaire? Et bien analysez bien le pourquoi dans votre cas. La paresse est souvent une bonne raison car on ne sait pas par où commencer. Avoir des classes à la responsabilité toujours plus concise possible simplifie énormément le temps à réfléchir à la conception et l’écriture de tests. Avoir des petits projets signifie des fonctionnalitées cadrées et dirigistes. Séparer vos blocs élémentaires vous mettra dans de bonne dispositions pour définir une architecture viable à long terme que vous ne voudrez plus changer. Pensez au futur!
Conclusion:
L'écriture de tests est un processus de développement qui est là pour prémunir de différentes erreurs que les développeurs laissent passer. Un bon outillage permet d’éviter d’avoir à faire ces vérifications manuellement et ainsi gagner énormément de temps.
Mais il ne faut surtout pas passer à côté de ce processus! Il peut être long pour différentes raisons : indisponibilité des personnes ayant connaissance du sujet, quantité de code trop large ou autre. Mais accélérer le processus ne signifie pas le négliger. Identifiez à chaque fois la raison de la perte de temps et essayez d’ajouter un outil pour automatiser ou accélérer le processus. La santée mentale de votre équipe ne pourra que s’en trouver améliorée.
Photo 1 by Annie Spratt on Unsplash