Mercredi 29 avril 2026
LLMOps : comment industrialiser l’IA sans tout casser en production
Déployer un modèle de langage en production n’est pas déployer une API REST. Ce n’est pas non plus déployer un modèle de machine learning classique. C’est un troisième type de problème — avec ses propres patterns de failure, ses propres métriques de santé, ses propres stratégies de retour arrière.
Le terme LLMOps est apparu pour nommer cette discipline. Il est imparfait, mais il signale quelque chose de réel : les pratiques MLOps et DevOps traditionnelles ne suffisent pas. Il faut les étendre, et sur certains points les repenser entièrement.
Cet article est une synthèse de ce que nous avons appris en déployant des systèmes basés sur des LLMs en production chez nos clients — pas une revue de frameworks, mais une carte des problèmes réels et des solutions qui fonctionnent.
Un appel à un LLM peut prendre entre 500 ms et 30 secondes selon le modèle, la longueur de la réponse et la charge du fournisseur. Votre client HTTP doit avoir des délais d'attente explicites et une stratégie de nouvelle tentative progressive. Une erreur 429, liée à une limite de débit, se gère différemment d’une erreur 503, liée à une indisponibilité du service. Il ne faut pas les traiter de la même façon.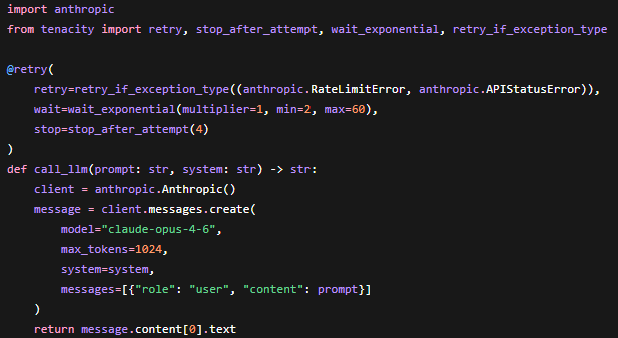 Modèle de secours
Modèle de secours
Avoir un modèle primaire et un modèle de secours, typiquement moins puissant ou moins coûteux, permet de maintenir le service en cas d’indisponibilité ou de dégradation du fournisseur principal. Ce n’est pas du confort d'ingénierie superflu : c’est de la résilience basique. Réponse progressive ou traitement par lot
Pour les interfaces utilisateur, l'affiche progressif de la réponse améliore radicalement la perception de performance. Pour les pipelines de traitement de données, le traitement par lot avec parallélisation contrôlée est souvent plus efficace et économique. Le choix impacte l’architecture de bout en bout.
Stockez vos prompts dans votre dépôt de code, pas dans une base de données ni dans du code en dur. Un changement de prompt doit passer par la même revue de code qu’un changement de logique métier — parce que c’est exactement ce que c’est. Structurer les modèles de prompts
Évitez la concaténation de chaînes de caractères pour assembler vos prompts. Utilisez un système de modèles qui rend explicites les variables, les sections conditionnelles et les limites de longueur.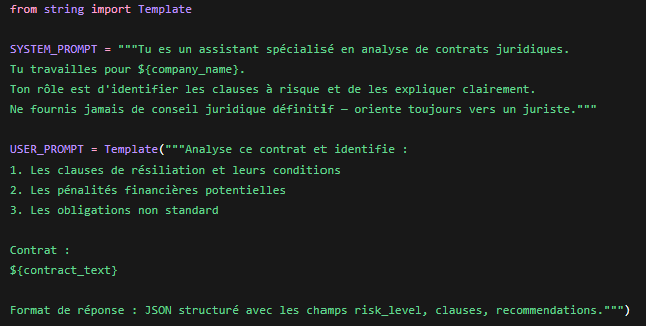 Test de régression sur prompts.
Test de régression sur prompts.
Définissez un ensemble de cas de test représentatifs — incluant des cas limites et des entrées adversariales — et exécutez-les à chaque modification de prompt. L’évaluation ne produit pas un booléen, mais un score sur des critères définis : exactitude, format, ton, pertinence.
Chaque requête qui traverse votre système doit porter un
LangSmith est le choix le plus mature pour le suivi spécifique aux LLM. Helicone et Langfuse sont de bonnes alternatives open-source. Pour les métriques opérationnelles standard — latence, erreurs — Datadog ou Prometheus/Grafana s’intègrent naturellement selon votre stack existante.
Les sorties LLM ne sont pas toujours comparables à une vérité terrain unique. “Explique ce concept” admet de nombreuses réponses correctes. L’évaluation doit donc être multidimensionnelle. LLM-as-judge.
Une pratique s’est largement démocratisée : utiliser un LLM, souvent un modèle plus puissant que celui en production, pour évaluer les sorties du modèle de production sur des critères définis. Ce n’est pas parfait, mais c’est scalable et suffisamment fiable pour détecter des régressions.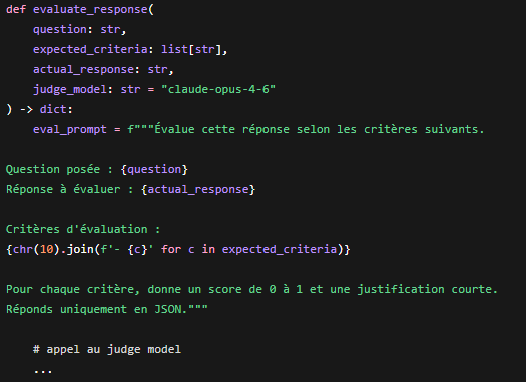 A/B testing de prompts.
A/B testing de prompts.
Avant de déployer un nouveau prompt en production, testez-le sur un sous-ensemble de trafic réel. La dégradation peut être imperceptible sur vos jeux de test et évidente sur les distributions réelles d’entrées utilisateurs.
Un utilisateur malveillant peut tenter d’injecter des instructions dans les données que votre système traite pour faire ignorer vos contraintes au modèle. Si votre pipeline traite du contenu utilisateur non filtré avant de l’envoyer au LLM, vous êtes exposé. Exfiltration via outputs.
Dans les systèmes où le LLM a accès à des données sensibles — base documentaire, emails, données client — l’output peut devenir un canal d’exfiltration si les contraintes ne sont pas correctement posées. La solution : définir explicitement dans le prompt système ce que le modèle est autorisé et interdit de restituer, puis valider les outputs avant restitution. Jailbreaking.
Sur les produits exposés au grand public, anticipez les tentatives de détournement. Les filtres d’inputs et la robustesse du prompt système sont votre première ligne de défense. Les API des grands fournisseurs intègrent des garde-fous natifs, mais ils ne sont pas suffisants seuls.
Qui est responsable de la qualité des prompts en production ? Qui a l’autorité de les modifier ? Qui valide avant déploiement ? Si la réponse est “n’importe qui”, vous avez un problème de gouvernance en attente. L’évaluation doit être une responsabilité partagée.
Les développeurs construisent le système d’évaluation, les experts métier définissent les critères. Externaliser entièrement l’évaluation aux développeurs produit des métriques techniques déconnectées de la valeur réelle. La supervision LLM doit entrer dans les procédures d'exploitation
Quand une alerte se déclenche sur le taux d’erreur de parsing des outputs, qui la reçoit ? Qui sait quoi faire ? Intégrez ces scénarios dans vos procédures d’astreinte comme n’importe quel autre service critique.
Pourquoi les LLMs cassent différemment
Commençons par comprendre pourquoi le sujet mérite une discipline à part. Un service classique échoue de manière binaire et bruyante : exception, timeout, code HTTP 5xx. Un LLM peut produire une réponse syntaxiquement valide, sémantiquement plausible, mais fonctionnellement catastrophique — et votre supervision technique ne verra rien. C’est le mode de failure le plus dangereux qui soit : silencieux et graduel. Deuxième différence : le non-déterminisme. À prompt identique, deux appels au même modèle peuvent produire des résultats différents. Cela rend les tests de régression classiques inapplicables tels quels, et le débogage d’un comportement spécifique en production particulièrement difficile. Troisième différence : la dépendance à des systèmes externes. La plupart des déploiements production utilisent des modèles via API : OpenAI, Anthropic, Google, Azure. Votre service hérite de la latence, de la disponibilité et des changements de comportement de ces fournisseurs — sans nécessairement être informé des modifications de modèle.Les cinq couches d’un pipeline LLM en production
1. La couche d’inférence
C’est là que réside la complexité opérationnelle la plus immédiate. Gestion des délais d'attente et des nouvelles tentativesUn appel à un LLM peut prendre entre 500 ms et 30 secondes selon le modèle, la longueur de la réponse et la charge du fournisseur. Votre client HTTP doit avoir des délais d'attente explicites et une stratégie de nouvelle tentative progressive. Une erreur 429, liée à une limite de débit, se gère différemment d’une erreur 503, liée à une indisponibilité du service. Il ne faut pas les traiter de la même façon.
Modèle de secoursAvoir un modèle primaire et un modèle de secours, typiquement moins puissant ou moins coûteux, permet de maintenir le service en cas d’indisponibilité ou de dégradation du fournisseur principal. Ce n’est pas du confort d'ingénierie superflu : c’est de la résilience basique. Réponse progressive ou traitement par lot
Pour les interfaces utilisateur, l'affiche progressif de la réponse améliore radicalement la perception de performance. Pour les pipelines de traitement de données, le traitement par lot avec parallélisation contrôlée est souvent plus efficace et économique. Le choix impacte l’architecture de bout en bout.
2. La couche de gestion des prompts
Un prompt est une dépendance applicative. Il a un comportement observable, il peut régresser, il doit être versionné. Versioning.Stockez vos prompts dans votre dépôt de code, pas dans une base de données ni dans du code en dur. Un changement de prompt doit passer par la même revue de code qu’un changement de logique métier — parce que c’est exactement ce que c’est. Structurer les modèles de prompts
Évitez la concaténation de chaînes de caractères pour assembler vos prompts. Utilisez un système de modèles qui rend explicites les variables, les sections conditionnelles et les limites de longueur.
Test de régression sur prompts.Définissez un ensemble de cas de test représentatifs — incluant des cas limites et des entrées adversariales — et exécutez-les à chaque modification de prompt. L’évaluation ne produit pas un booléen, mais un score sur des critères définis : exactitude, format, ton, pertinence.
3. La couche d’observabilité
Sans observabilité, vous opérez à l’aveugle. Avec une observabilité mal conçue, vous vous noyez sous des données inutiles. Voici ce qui compte vraiment. Les métriques à instrumenter :- Latence p50, p95, p99 par point d’entrée et par modèle, afin de mesurer non seulement le temps de réponse médian, mais aussi les ralentissements observés sur les requêtes plus longues.
- Taux d’erreur par type : timeout, limite de débit, erreur de parsing de l’output, refus du modèle
- Coût par requête et par feature, car les surprises de facture arrivent vite
- Longueur des inputs et outputs, car les dérives de longueur signalent souvent des problèmes en amont
- Taux de validation échouée sur les outputs structurés
Chaque requête qui traverse votre système doit porter un
trace_id propagé à tous les appels LLM. Quand un comportement inattendu remonte du terrain, vous devez pouvoir reconstituer la séquence complète : input utilisateur, prompt assemblé, réponse brute du modèle, output final.
Les outils.LangSmith est le choix le plus mature pour le suivi spécifique aux LLM. Helicone et Langfuse sont de bonnes alternatives open-source. Pour les métriques opérationnelles standard — latence, erreurs — Datadog ou Prometheus/Grafana s’intègrent naturellement selon votre stack existante.
4. La couche d’évaluation continue
C’est probablement la couche la plus sous-investie dans la plupart des projets. Pourquoi l’évaluation classique ne suffit pas.Les sorties LLM ne sont pas toujours comparables à une vérité terrain unique. “Explique ce concept” admet de nombreuses réponses correctes. L’évaluation doit donc être multidimensionnelle. LLM-as-judge.
Une pratique s’est largement démocratisée : utiliser un LLM, souvent un modèle plus puissant que celui en production, pour évaluer les sorties du modèle de production sur des critères définis. Ce n’est pas parfait, mais c’est scalable et suffisamment fiable pour détecter des régressions.
A/B testing de prompts.Avant de déployer un nouveau prompt en production, testez-le sur un sous-ensemble de trafic réel. La dégradation peut être imperceptible sur vos jeux de test et évidente sur les distributions réelles d’entrées utilisateurs.
5. La couche de sécurité
Les vecteurs d’attaque spécifiques aux LLMs sont réels et sous-estimés. Prompt injection.Un utilisateur malveillant peut tenter d’injecter des instructions dans les données que votre système traite pour faire ignorer vos contraintes au modèle. Si votre pipeline traite du contenu utilisateur non filtré avant de l’envoyer au LLM, vous êtes exposé. Exfiltration via outputs.
Dans les systèmes où le LLM a accès à des données sensibles — base documentaire, emails, données client — l’output peut devenir un canal d’exfiltration si les contraintes ne sont pas correctement posées. La solution : définir explicitement dans le prompt système ce que le modèle est autorisé et interdit de restituer, puis valider les outputs avant restitution. Jailbreaking.
Sur les produits exposés au grand public, anticipez les tentatives de détournement. Les filtres d’inputs et la robustesse du prompt système sont votre première ligne de défense. Les API des grands fournisseurs intègrent des garde-fous natifs, mais ils ne sont pas suffisants seuls.
Retour terrain : structurer un projet LLM pour le rendre industrialisable
Au-delà des principes, le LLMOps prend tout son sens lorsqu’il est appliqué à des projets réels, avec des contraintes de livraison, de traçabilité et d’intégration dans une chaîne DevOps existante. Ronan, Olymppien, a récemment travaillé sur la mise en production de solutions LLM dans un contexte de projet créé from scratch, sans dette technique initiale. Le projet avait été construit initialement en monorepo et amorcé dans une logique de vibe coding. L’enjeu était donc clair : passer d’un usage exploratoire des LLMs à un système structuré, maîtrisable et exploitable dans un environnement projet réel. Comme il le résume : “Le risque principal était d’avoir des agents produisant des outputs non maîtrisés, non reproductibles et difficilement intégrables dans une chaîne de livraison classique.” Pour répondre à cet enjeu, l’équipe a mis en place un workflow LLMOps basé sur une orchestration multi-agents via BMAD. L’objectif était de structurer les rôles des agents — architecture, développement, review — tout en assurant une traçabilité des actions et une mémoire des décisions prises. Ronan explique que BMAD a également été utilisé en amont pour cadrer le besoin : “À partir d’un template HTML et d’un cahier des charges, les agents permettent de formaliser l’architecture, découper les fonctionnalités et générer des tickets exploitables.” Cette approche permet d’éviter les interprétations floues, de clarifier rapidement les aspects fonctionnels et techniques, et de produire des éléments directement utilisables par les équipes projet. Un autre point important du dispositif reposait sur des prompts dynamiques. Un fichier central définissait les règles, le contexte projet et l'enchaînement des actions à suivre. Ce cadrage permettait à l’IA de générer des actions plus cohérentes et reproductibles, au lieu de dépendre uniquement d’instructions ponctuelles ou dispersées. Ronan insiste aussi sur l’introduction de capacités contrôlées exposées au LLM. Plutôt que de laisser l’agent agir uniquement via du prompt libre, certaines actions étaient encadrées : interactions avec GitLab, Jira, ou déclenchement de workflows CI/CD Jenkins. “Cela permet de limiter les actions imprévues, de mieux contrôler les effets de bord et de rapprocher l’usage du LLM d’un modèle outillé et sécurisé.” L’ensemble a été intégré dans une chaîne DevOps classique : GitLab, Jira, CI/CD Jenkins, déploiement Kubernetes avec Helm et Argo CD, et isolation des développements via Git worktrees. Cette architecture permet de conserver des pratiques standards — versioning, review, rollback — malgré l’usage d’agents IA. Ce retour d’expérience illustre précisément ce que recouvre le LLMOps : il ne s’agit pas simplement “d’utiliser un LLM”, mais de l’encadrer avec des workflows, des rôles, des capacités limitées et une intégration au cycle de livraison existant. C’est ce qui permet de passer d’un usage expérimental à un système réellement industrialisable.La question du construire ou acheter
Une décision structurante se pose rapidement : construire votre propre infrastructure d’inférence ou utiliser les APIs des grands fournisseurs ? Utiliser les APIs — OpenAI, Anthropic, Google — permet un time-to-market rapide, une maintenance opérationnelle réduite et un accès aux modèles les plus récents. La contrepartie : dépendance fournisseur, coût variable difficile à maîtriser à grande échelle, absence de contrôle sur le modèle exact utilisé, contraintes de confidentialité des données. Héberger vos propres modèles — avec Ollama, vLLM, TGI — donne davantage de contrôle, un coût plus prévisible à fort volume et des données qui ne quittent pas votre infrastructure. La contrepartie : un gap de performance significatif avec les modèles frontier, une expertise DevOps spécialisée et une maintenance non triviale. Notre position : pour la majorité des cas d’usage enterprise, les APIs managées sont le bon point de départ. L’hébergement propre devient pertinent quand les volumes justifient l’investissement opérationnel, quand les contraintes de souveraineté des données sont fortes, ou quand un modèle fine-tuné sur votre domaine dépasse les modèles génériques sur votre cas d’usage spécifique.Ce que ça change dans votre organisation
Le LLMOps ne se résume pas à des choix techniques. Il change aussi les responsabilités dans l’équipe. Le rôle du prompt engineer doit être formalisé.Qui est responsable de la qualité des prompts en production ? Qui a l’autorité de les modifier ? Qui valide avant déploiement ? Si la réponse est “n’importe qui”, vous avez un problème de gouvernance en attente. L’évaluation doit être une responsabilité partagée.
Les développeurs construisent le système d’évaluation, les experts métier définissent les critères. Externaliser entièrement l’évaluation aux développeurs produit des métriques techniques déconnectées de la valeur réelle. La supervision LLM doit entrer dans les procédures d'exploitation
Quand une alerte se déclenche sur le taux d’erreur de parsing des outputs, qui la reçoit ? Qui sait quoi faire ? Intégrez ces scénarios dans vos procédures d’astreinte comme n’importe quel autre service critique.