Lundi 8 janvier 2024
L’art du Clean Code : concept et conseils
Symptôme d’un mauvais code
- Rigidité : On dit qu’une application est rigide lorsqu’elle est difficile à changer et qu’une modification entraine une cascade de changements par la suite.
- Fragilité : Un code est fragile si l’application peut se casser à plusieurs endroits à cause d’un seul changement.
- Immobilité : Le code n’est pas réutilisable.
- Opacité : Le code est difficile à comprendre
Pourquoi écrivons-nous du mauvais code ?
Le développeur ne prend pas plaisir à écrire du mauvais code, il ne le fait souvent pas exprès. Cela peut venir d’un manque de compréhension de bonnes pratiques, mais souvent on nous répondra que c’est pour aller plus vite. Ce qui peut être contradictoire, car pour aller plus vite on écrit du mauvais code, mais ce mauvais code peut introduire des symptômes (rigidité, fragilité, immobilité, opacité …) impliquant une perte de temps. ⭐ En pratique il est vrai que cela peut aller plus vite d’écrire du mauvais code, la fonctionnalité est simple, ce sont des méthodes que l’on connait. Mais sur l’échelle d’un projet, cela peut être différent. La seule façon d’aller vite est d’écrire du bon code. Écrire du bon code est un investissement important pour le développeur, mais aussi pour le projet qui aura toujours des besoins évolutifs. Cet investissement n’est pas à perte, car beaucoup de méthodes clean code existent depuis plusieurs décennies et restent valables dans les standards de programmation d’aujourd’hui. ✅ Écrire du code qu’une machine peut comprendre est simple. Cependant, écrire du code qu’un humain peut comprendre est plus compliqué. Dans certains cas un développeur peut passer plus de temps à lire du code qu’à en produire. Lorsque l’on code il faut penser plus au développeur qu’à la machine ?Règles générales
Suivez les conventions
Cela peut paraître simple, mais c’est très important. Quand on parle de conventions on parle de toutes les conventions possibles. Et le plus important c’est de choisir une convention et de la respecter partout dans le projet. Exemple :- Règle de conventions de nommage des méthodes et variables
- Pour le Rest utiliser la convention Restful
- Respect de l’architecture du projet
- Règle interne au projet
La règle du Boy-scout
 ? Laissez toujours le terrain de camping plus propre que vous ne l’avez trouvé.
Dans un projet, il sera toujours plus intéressant d’intervenir lors d’une évolution sur une partie de code quand on remarque une mauvaise pratique, que de se lancer dans une tache de refactorisation du code dans l’ensemble du projet. Ainsi après l’intervention ce morceau de code a été rendu meilleur qu’il n’a été avant.
⭐ Si cela est fait collectivement le projet n’aura pas besoin d’être refactoré dans son ensemble.
? Laissez toujours le terrain de camping plus propre que vous ne l’avez trouvé.
Dans un projet, il sera toujours plus intéressant d’intervenir lors d’une évolution sur une partie de code quand on remarque une mauvaise pratique, que de se lancer dans une tache de refactorisation du code dans l’ensemble du projet. Ainsi après l’intervention ce morceau de code a été rendu meilleur qu’il n’a été avant.
⭐ Si cela est fait collectivement le projet n’aura pas besoin d’être refactoré dans son ensemble.
Le DRY (Ne vous répétez pas)
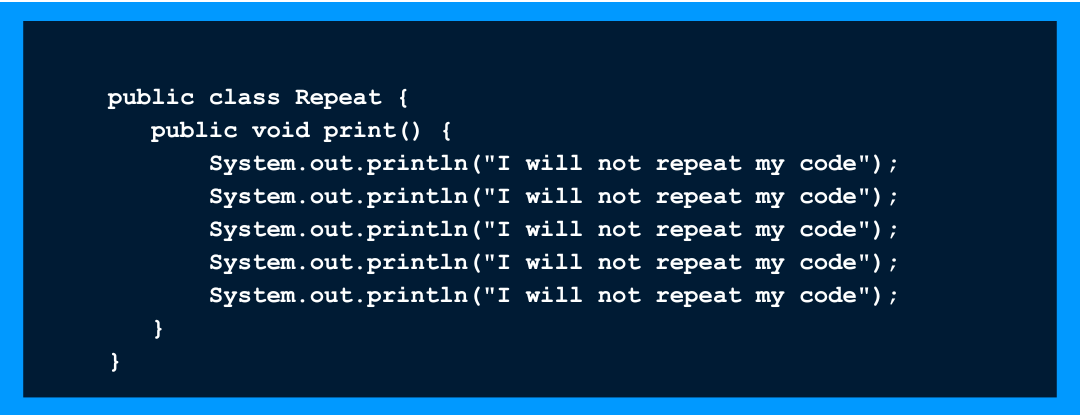 Un principe très important, qui coûte très peu à mettre en place mais qui a énormément d’avantages. C’est probablement le principe le plus important à mettre en place avant de penser à des règles plus complexes.
? Chaque élément de connaissance ou de logique doit avoir une représentation unique et non-ambiguë au sein d’un système.
Nous allons aborder trois types de répétition.”
Un principe très important, qui coûte très peu à mettre en place mais qui a énormément d’avantages. C’est probablement le principe le plus important à mettre en place avant de penser à des règles plus complexes.
? Chaque élément de connaissance ou de logique doit avoir une représentation unique et non-ambiguë au sein d’un système.
Nous allons aborder trois types de répétition.”
Abstraction
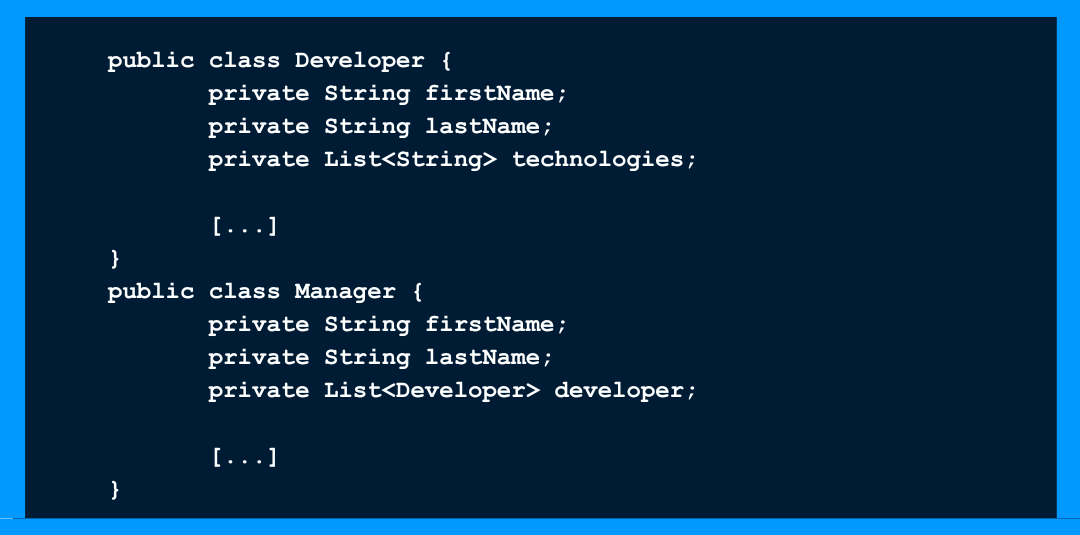 On remarque tout de suite des répétitions au niveau des propriétés, et donc on crée une abstraction plus élevée.
On remarque tout de suite des répétitions au niveau des propriétés, et donc on crée une abstraction plus élevée.
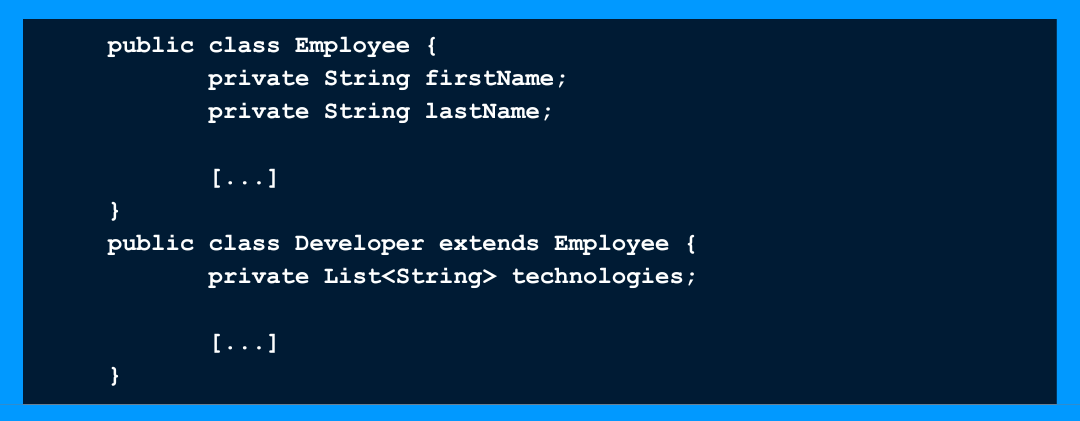
Block
Des blocs de code qui sont répétés plusieurs fois, en général c’est aussi résolu avec un peu d’héritage ou une méthode simple si la répétition est dans la même classe.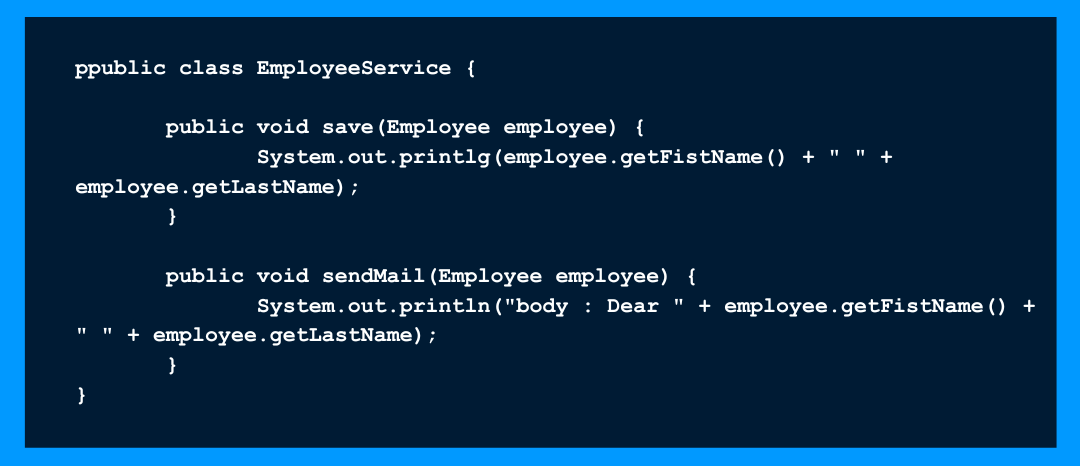 La récupération du nom et du prénom du salarié est répétée deux fois, on peut décider de faire porter la récupération à la classe Employee.
La récupération du nom et du prénom du salarié est répétée deux fois, on peut décider de faire porter la récupération à la classe Employee.
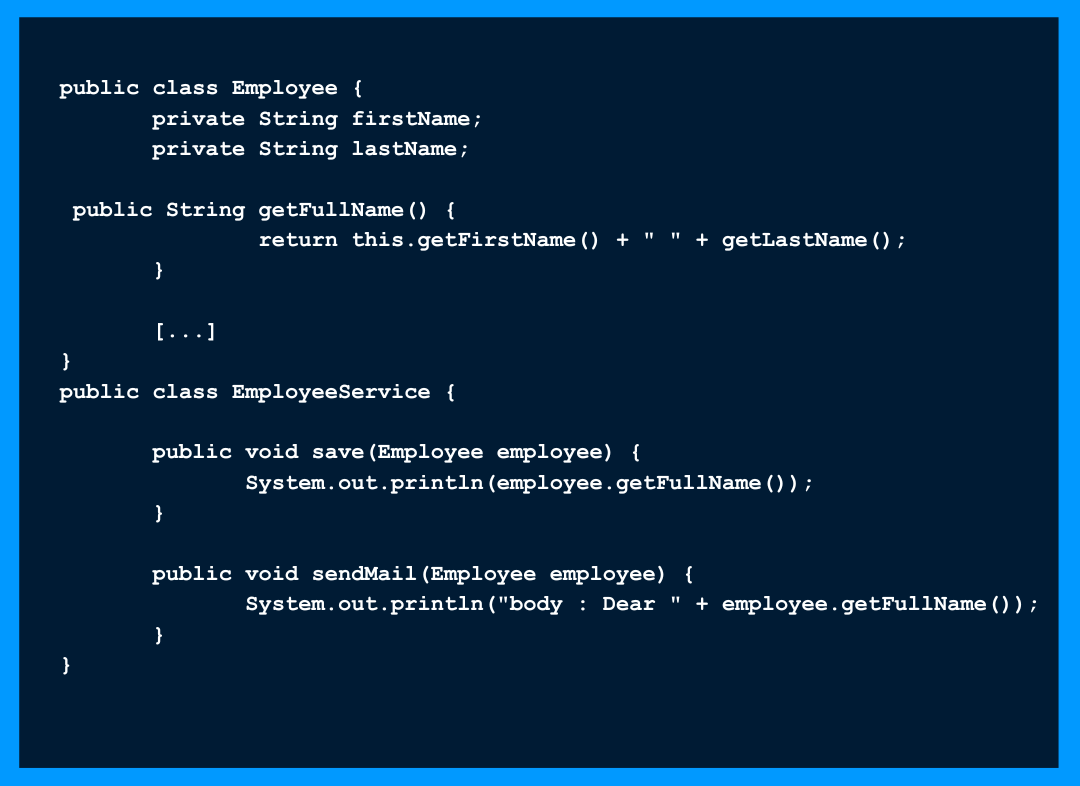 ✏️ Dans le cas où on a besoin de faire une modification sur le nom/prénom, comme l’ajout d’un tiret entre les deux, on aura dans un cas la modification de toutes les répétitions dans le code et dans l’autre la modification de la méthode getFullName() uniquement.
✏️ Dans le cas où on a besoin de faire une modification sur le nom/prénom, comme l’ajout d’un tiret entre les deux, on aura dans un cas la modification de toutes les répétitions dans le code et dans l’autre la modification de la méthode getFullName() uniquement.
Template
Cas d’une application utilisant des requêtes pour une base de données.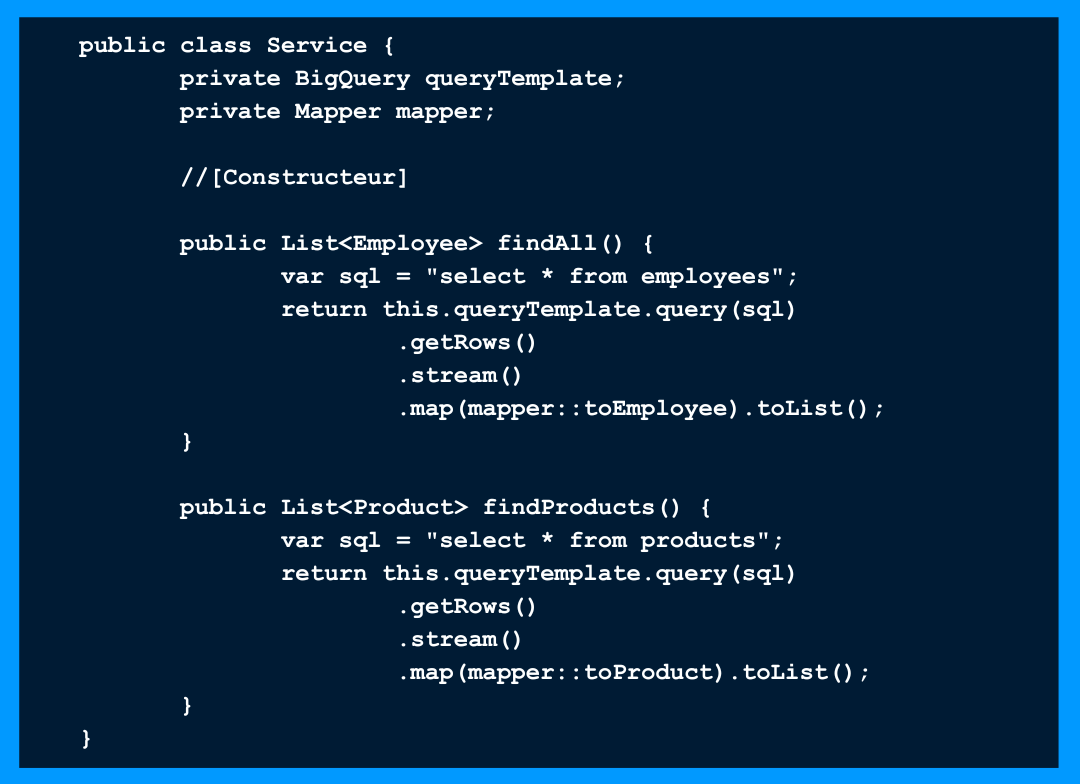 Ce qui est répété ici ce n’est pas le bloc de code mais sa structure logique. Pour éviter la répétition on peut créer un Template.
Ce qui est répété ici ce n’est pas le bloc de code mais sa structure logique. Pour éviter la répétition on peut créer un Template.
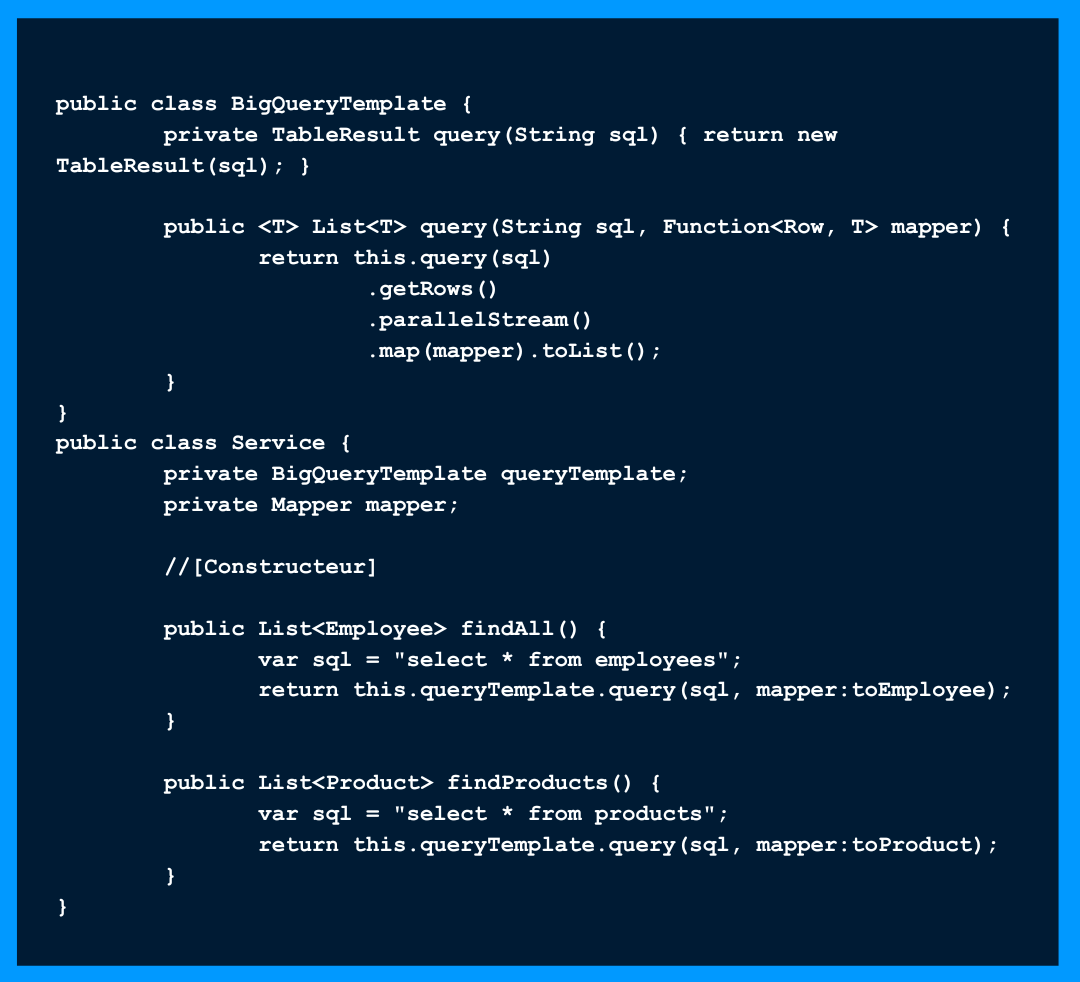 ✏️ Dans le cas où on a besoin de faire une modification de logique comme ici le parallelStream, on aura uniquement à modifier la logique une seule fois dans la classe BigQueryTemplate.
✏️ Dans le cas où on a besoin de faire une modification de logique comme ici le parallelStream, on aura uniquement à modifier la logique une seule fois dans la classe BigQueryTemplate.
YAGNI (Vous n’en aurez pas besoin)
? Mettez toujours en œuvre les choses lorsque vous en avez réellement besoin, jamais lorsque vous prévoyez que vous en aurez probablement besoin plus tard. En tant que développeur il a parfois était envisageable d’effectué des développements supplémentaire sur un service en prévision de futures fonctionnalités. L’idée principale de YAGNI est de ne pas anticiper mais d’attendre que le besoin soit clair pour développer uniquement ce besoin. Cette bonne pratique est aussi mise en place par le TDD qui consiste à tester uniquement des fonctionnalités qui sont précisément ciblées sans sortir du contexte.KISS (Keep it Simple, Stupid / Keep it short and Simple)
Ce principe provient de l’industrie aéronautique, un ingénieur poussa l’idée que l’avion a créer doit être réparable n’importe où, par un mécanicien de compétence moyenne et un set d’outils précis. En transposant ça pour les développeurs, le code doit être simple pour être compris par n’importe qui, et pouvant être modifié ou corrigé sans difficulté. On peut donner le cas d’une méthode trop longue, + de 20 lignes même si cela est subjectif. Dans ce cas il faut réfléchir à comment rendre ce code plus simple (Meilleur utilisation des bibliothèques, séparation des différentes logiques comprises dans une unique méthode)Newspaper Style
 Les titres les plus importants d’un journal sont les titres les plus grands, ici c’est pareil pour class, les fonctions les plus importantes sont mises en haut (constructeur …) et les moins importantes en bas (fonction private …).
Les titres les plus importants d’un journal sont les titres les plus grands, ici c’est pareil pour class, les fonctions les plus importantes sont mises en haut (constructeur …) et les moins importantes en bas (fonction private …).
SOLID
Ce sont des principes résumés par Uncle Bob (Rober C. Martin), remontant aux années 1970, qui sont toujours d’actualité. SOLID est composé de cinq principes.Single responsibility principle
? Une classe devrait avoir une, et une seule raison de changer. Cas : Un module qui affiche des factures en format pdf, qui est décomposé simplement par un module de création de pdf, un service de traitement de données et d’une structure de stockage. Pour le module de création de pdf, il ne peut pas y avoir de modification en cas de changement sur l’algorithme ou si la source de donnée change, sa seule raison de changer est si le rendu pdf change. L’exemple ci-dessus n’est pas en SRP car il inclut 3 responsabilités (http, jdbc et logique métier).
L’exemple ci-dessus n’est pas en SRP car il inclut 3 responsabilités (http, jdbc et logique métier).
Open Closed principle
? Les objets ou entités doivent être ouverts pour extension mais fermés pour modification. Cas : Une class qui va agréger des données provenant de différentes sources.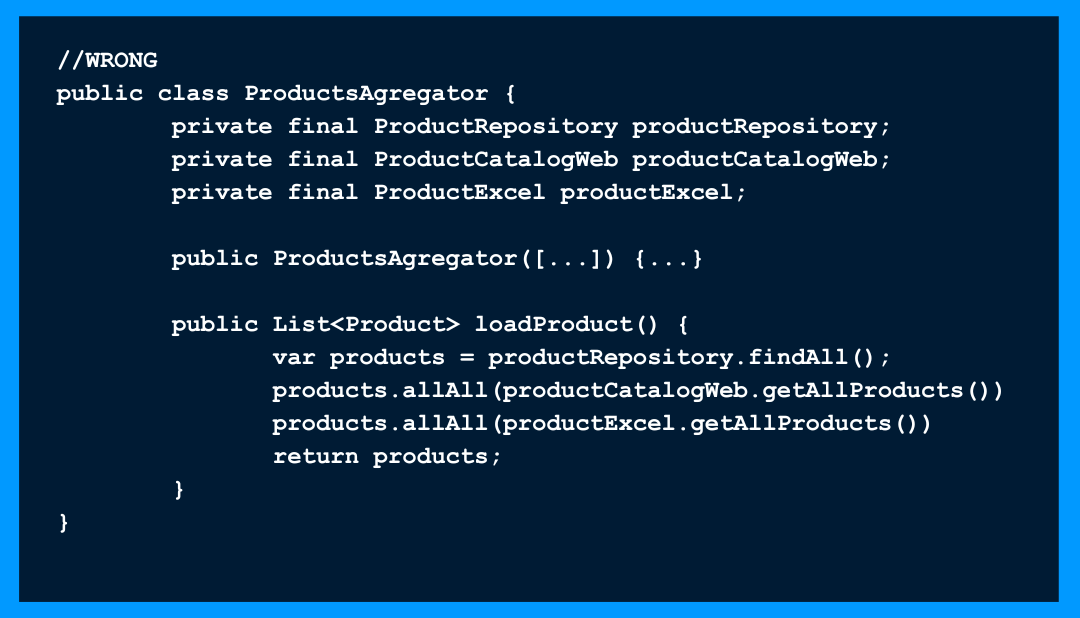 Le problème qui se pose est que s’il existe une nouvelle source de données, on sera obligé de l’ajouter à divers endroits et de changer le code de la class. Il peut être recommandé d’utiliser la méthode suivante :
Le problème qui se pose est que s’il existe une nouvelle source de données, on sera obligé de l’ajouter à divers endroits et de changer le code de la class. Il peut être recommandé d’utiliser la méthode suivante :
 Avec chaque provider implémentant l’interface ProductProvider qui contient la méthode load().
Avec chaque provider implémentant l’interface ProductProvider qui contient la méthode load().
 Ainsi l’ajout d’un provider ne modifie pas la class ProductsAgregator. Il suffit juste de créer une nouvelle class contenant le nouveau type de provider.
Ainsi l’ajout d’un provider ne modifie pas la class ProductsAgregator. Il suffit juste de créer une nouvelle class contenant le nouveau type de provider.
Liskov Substitution Principle
? Soit q(x) une propriété prouvable sur les objets x de type T. Alors q(y) devrait être prouvable pour les objets y de type S où S est un sous-type de T. Autrement dit, si un type S hérite de T, il est donc possible de remplacer dans l’application T par S sans qu’il y ait de problème. Il est souvent dit dans l’héritage que B hérite de A si B est un A (exemple véhicule/voiture). Liskov voit les choses différemment, une classe B doit hériter de A si B se comporte comme A. L’exemple le plus connu est celui du carré et du rectangle. Mathématiquement, un carré est un rectangle, en revanche, en cas d’héritage entre une carré et un rectangle, le carré ne se comporte pas comme un rectangle car pour un carré on a besoin de connaitre un seul côté alors que pour les rectangles les deux cotés adjacents sont nécessaires. Ce cas ne respecte pas le principe de Liskov.Interface Segregation Principle ? Un client ne devrait jamais être obligé d’implémenter une interface qu’il n’utilise pas, ou les clients ne devraient pas être obligés de dépendre de méthodes qu’ils n’utilisent pas.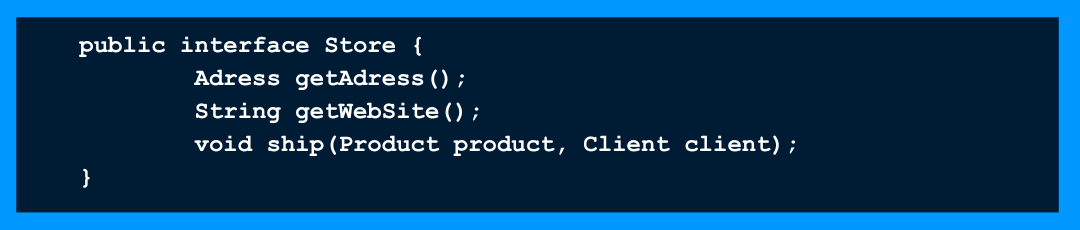 Cela peut nous paraitre correct mais il peut exister des magasins sans site web ou sans adresse physique ou sans expédition. La solution serait de séparer ces possibilités en plusieurs interfaces.
Cela peut nous paraitre correct mais il peut exister des magasins sans site web ou sans adresse physique ou sans expédition. La solution serait de séparer ces possibilités en plusieurs interfaces.
 De cette façon il sera possible d’implémenter un magasin avec un ou plusieurs interfaces que l’on a choisies.
? Un non-respect de ce principe peut engendrer aussi une violation du principe de Liskov.
De cette façon il sera possible d’implémenter un magasin avec un ou plusieurs interfaces que l’on a choisies.
? Un non-respect de ce principe peut engendrer aussi une violation du principe de Liskov.
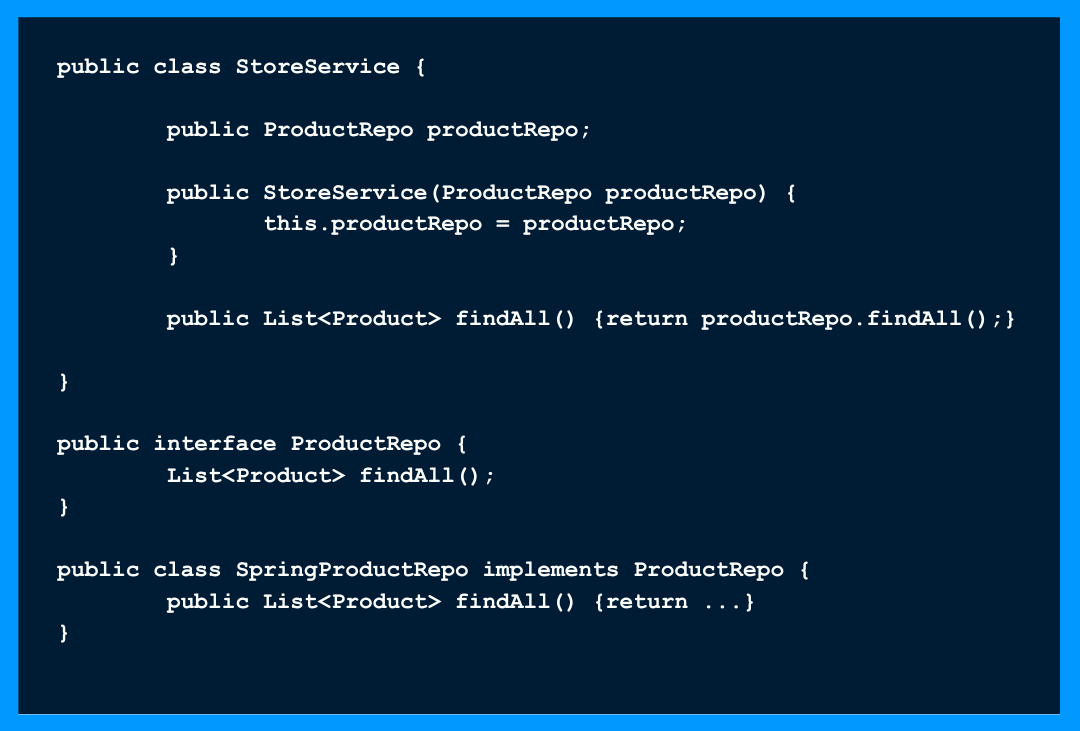
Dependency Inversion Principle
? Les entités doivent dépendre d’abstraction, pas de concrétions. Il stipule que le module de haut niveau ne doit pas dépendre du module de bas niveau, mais qu’il doit dépendre d’abstraction. Juste en ajoutant une interface intermédiaire le flux d’exécution est inversé et le StoreService ne dépend plus de SpringProductRepo
Juste en ajoutant une interface intermédiaire le flux d’exécution est inversé et le StoreService ne dépend plus de SpringProductRepo
par Emile