Mercredi 17 juin 2026
Gérer la fenêtre de contexte : le problème que tout le monde sous-estime
200 000 tokens de contexte, ça semble illimité. Ça ne l'est pas. Entre coût, dégradation silencieuse des performances et latence qui s'envole, la gestion du contexte est devenue une compétence d'architecture à part entière.
 La zone qui explose le plus souvent : les documents RAG. Sans budget tokens explicite par zone, un retrieval un peu trop généreux peut saturer le contexte et laisser moins de place à l'historique — ou pire, forcer une troncature silencieuse.
La zone qui explose le plus souvent : les documents RAG. Sans budget tokens explicite par zone, un retrieval un peu trop généreux peut saturer le contexte et laisser moins de place à l'historique — ou pire, forcer une troncature silencieuse.

 Ne compressez pas trop tôt. Chaque compression introduit une perte d'information irréversible. Définissez un seuil clair (ex : compression uniquement au-delà de 80% du budget historique) et loguez chaque événement de compression pour pouvoir détecter les cas où elle dégrade la qualité.
Ne compressez pas trop tôt. Chaque compression introduit une perte d'information irréversible. Définissez un seuil clair (ex : compression uniquement au-delà de 80% du budget historique) et loguez chaque événement de compression pour pouvoir détecter les cas où elle dégrade la qualité.
Le piège du "contexte infini"
Quand Anthropic a sorti Claude avec 200k tokens de contexte, beaucoup d'équipes ont eu la même réaction : "Problème résolu, on met tout dedans." C'est une erreur. Pas parce que les modèles ne peuvent pas traiter autant de tokens — ils le peuvent — mais pour trois raisons bien documentées. Premièrement, le coût. À 3$ les 1000 tokens input sur un modèle récent, remplir 150k tokens à chaque appel coûte 0,45$ par requête. Sur 100 000 appels par jour, ça fait 45 000$ quotidiens — uniquement en input tokens, avant même de compter l'output. Deuxièmement, le phénomène lost in the middle. Des recherches publiées en 2023 puis confirmées depuis montrent que les LLMs ont du mal à retrouver des informations placées au milieu d'un long contexte. Les informations en début et en fin de contexte sont bien mieux mémorisées. Plus votre contexte est long, plus ce biais s'aggrave. Troisièmement, la latence. Le time-to-first-token croît avec la taille du contexte. Sur des contextes très longs, vous pouvez attendre plusieurs secondes avant le premier token — même en streaming, l'UX en souffre. Règle des 80/20 du contexte : dans la plupart des applications, 80% de la valeur vient de 20% du contenu injecté. La discipline de gestion de contexte consiste à identifier et prioriser ce 20%.Ce que contient vraiment votre contexte
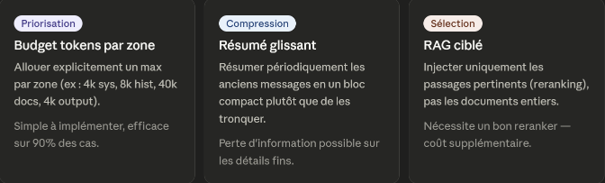
Avant d'optimiser, cartographiez. Un contexte typique d'application IA se décompose en quatre zones :
La zone qui explose le plus souvent : les documents RAG. Sans budget tokens explicite par zone, un retrieval un peu trop généreux peut saturer le contexte et laisser moins de place à l'historique — ou pire, forcer une troncature silencieuse.
Quatre stratégies concrètes
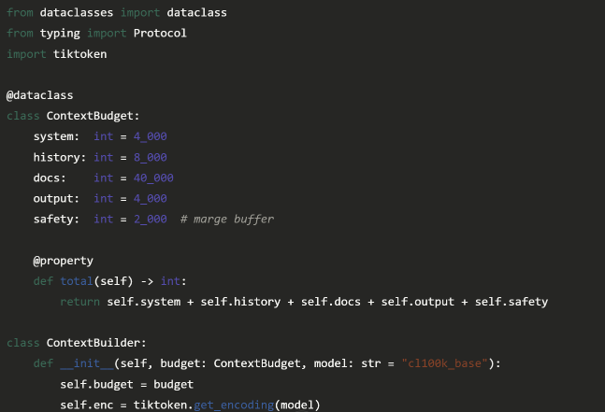
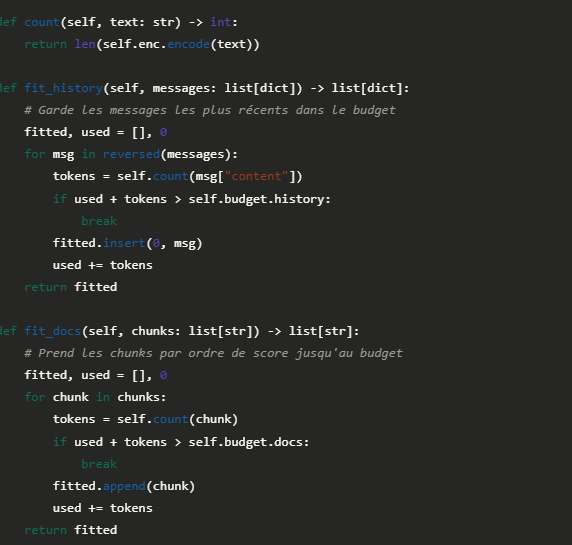
Implémenter un budget tokens robuste
Voici un pattern de gestion de contexte qu'on retrouve dans les architectures les plus solides. L'idée : chaque composant déclare son budget, et un orchestrateur central garantit qu'on ne dépasse pas la limite :
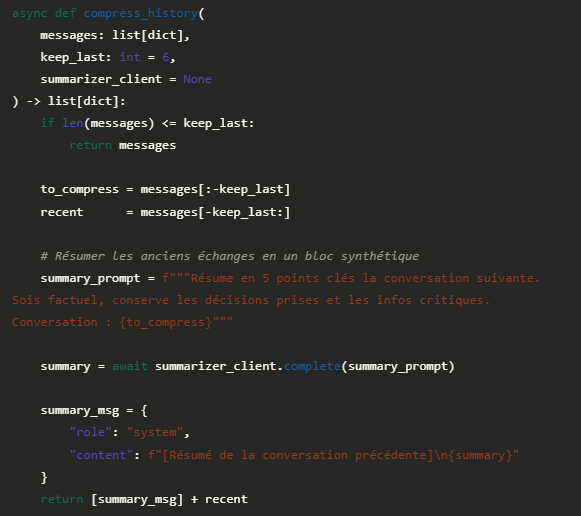
Le résumé glissant : ne jamais tronquer bêtement
Tronquer l'historique en coupant les vieux messages est la solution naïve. Elle fait perdre le contexte de la conversation — et l'utilisateur le ressent immédiatement quand l'assistant "oublie" ce qui a été dit. Une meilleure approche : compresser par résumé.
Ne compressez pas trop tôt. Chaque compression introduit une perte d'information irréversible. Définissez un seuil clair (ex : compression uniquement au-delà de 80% du budget historique) et loguez chaque événement de compression pour pouvoir détecter les cas où elle dégrade la qualité.
Ce qu'il faut monitorer
La gestion de contexte sans observabilité, c'est de l'optimisation aveugle. Trois métriques à suivre en priorité :- Tokens input par zone (système, historique, docs) — pour détecter les zones qui dérivent.
- Taux de troncature — combien de requêtes ont nécessité une compression ou une coupe. Un taux élevé révèle un problème de design.
- Corrélation tokens / qualité perçue — si vous avez du feedback utilisateur, croisez-le avec la taille du contexte. Vous verrez souvent une dégradation au-delà d'un certain seuil.