Mercredi 10 juin 2026
Fine-tuning ou prompting : arrêtez de choisir par défaut
"On va fine-tuner le modèle." Cette phrase est prononcée trop tôt, trop souvent, pour de mauvaises raisons. Voici un guide pour choisir la bonne approche — et surtout ne pas gaspiller trois semaines sur la mauvaise.
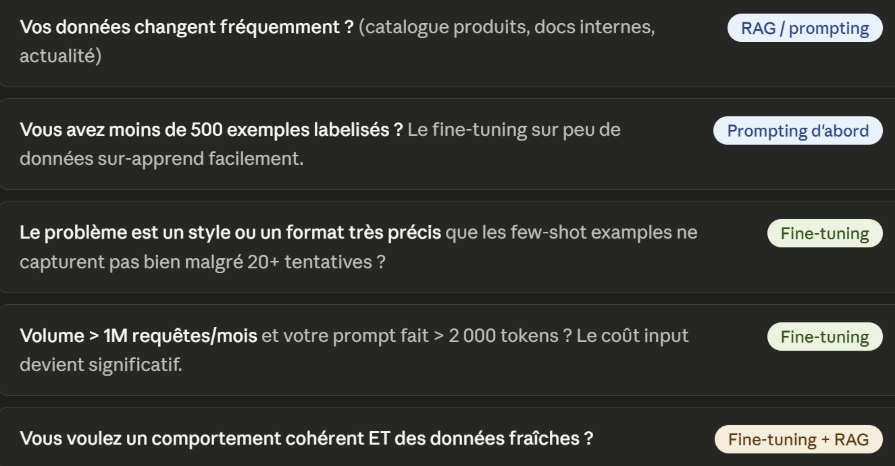
 Remarquez ce qui n'est pas dans la colonne fine-tuning : "ajouter des connaissances récentes", "accéder à des données internes", "personnaliser par utilisateur". Ce sont des cas de RAG — Retrieval-Augmented Generation, ou génération augmentée par récupération : le modèle va chercher des informations dans une base documentaire avant de répondre — pas des cas de fine-tuning. La confusion entre les deux est la source d'erreurs de conception les plus coûteuses qu'on voit en mission.
Remarquez ce qui n'est pas dans la colonne fine-tuning : "ajouter des connaissances récentes", "accéder à des données internes", "personnaliser par utilisateur". Ce sont des cas de RAG — Retrieval-Augmented Generation, ou génération augmentée par récupération : le modèle va chercher des informations dans une base documentaire avant de répondre — pas des cas de fine-tuning. La confusion entre les deux est la source d'erreurs de conception les plus coûteuses qu'on voit en mission.
 Avec ce niveau de structuration, un modèle généraliste produit des résumés très cohérents. Le fine-tuning n'apporte une valeur mesurable que si vous avez des centaines d'exemples validés par des humains et que la cohérence reste insuffisante après optimisation du prompt.
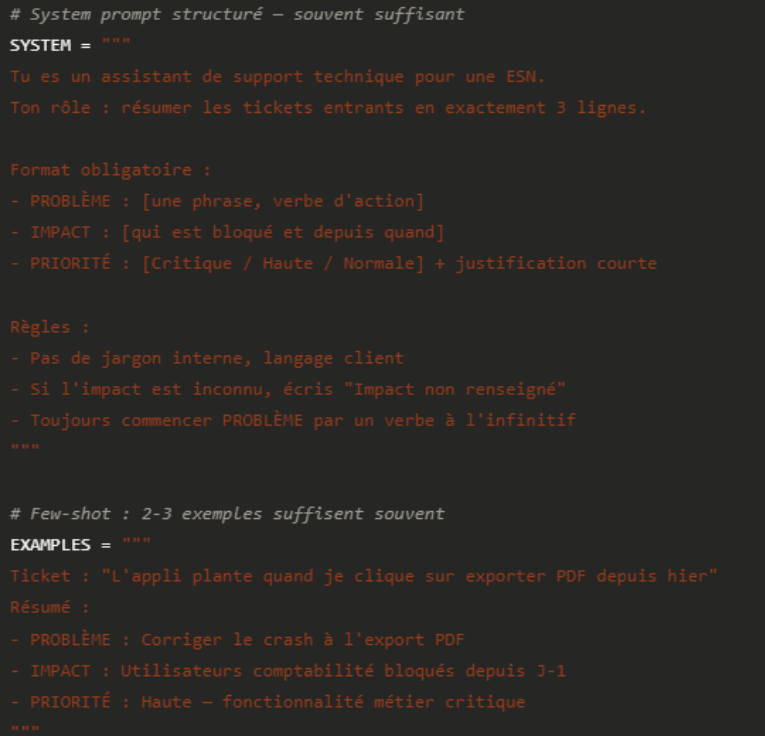
Avec ce niveau de structuration, un modèle généraliste produit des résumés très cohérents. Le fine-tuning n'apporte une valeur mesurable que si vous avez des centaines d'exemples validés par des humains et que la cohérence reste insuffisante après optimisation du prompt.
 Attention au dataset drift. Un modèle fine-tuné est figé dans le temps. Si votre domaine évolue (nouvelles réglementations, nouveau jargon, nouveaux produits), votre modèle dérive silencieusement. Prévoyez dès le départ un pipeline de ré-entraînement périodique — sinon le fine-tuning devient une dette technique.
Attention au dataset drift. Un modèle fine-tuné est figé dans le temps. Si votre domaine évolue (nouvelles réglementations, nouveau jargon, nouveaux produits), votre modèle dérive silencieusement. Prévoyez dès le départ un pipeline de ré-entraînement périodique — sinon le fine-tuning devient une dette technique.
Le malentendu de départ
Beaucoup d'équipes pensent au fine-tuning dès qu'elles veulent "personnaliser" un LLM. L'idée est intuitive : si le modèle ne se comporte pas exactement comme on veut, on l'entraîne davantage. Mais cette analogie avec le machine learning classique est trompeuse. Les LLMs modernes sont déjà extraordinairement capables. Dans la majorité des cas, ce qui manque n'est pas de la connaissance supplémentaire dans les poids du modèle — c'est de la clarté dans les instructions. Le fine-tuning règle rarement un problème de prompt mal conçu. Règle empirique : si vous n'avez pas encore épuisé les possibilités du prompting — few-shot examples, chain-of-thought, contraintes de format, system prompt structuré — le fine-tuning ne résoudra probablement pas votre problème. Il le cachera.Ce que chacun résout vraiment
Remarquez ce qui n'est pas dans la colonne fine-tuning : "ajouter des connaissances récentes", "accéder à des données internes", "personnaliser par utilisateur". Ce sont des cas de RAG — Retrieval-Augmented Generation, ou génération augmentée par récupération : le modèle va chercher des informations dans une base documentaire avant de répondre — pas des cas de fine-tuning. La confusion entre les deux est la source d'erreurs de conception les plus coûteuses qu'on voit en mission.
L'arbre de décision pragmatique
Concrètement : un cas de prompting bien fait
Prenons un cas réel : générer des résumés de tickets de support dans un format maison. La tentation est de fine-tuner. Voici ce qu'un prompt structuré peut accomplir :
Avec ce niveau de structuration, un modèle généraliste produit des résumés très cohérents. Le fine-tuning n'apporte une valeur mesurable que si vous avez des centaines d'exemples validés par des humains et que la cohérence reste insuffisante après optimisation du prompt.
Quand le fine-tuning vaut vraiment la peine
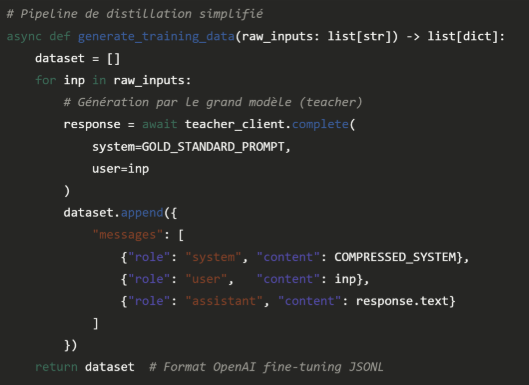
Voici trois situations où le fine-tuning est le bon outil : Le style est un actif différenciant Un éditeur juridique qui veut que chaque clause générée respecte sa doctrine interne — des décennies de jurisprudence maison. Aucun prompt ne capture ça. Un dataset de 2 000 paires (brouillon → clause validée) par des juristes seniors, oui. La latence est une contrainte dure Si vous avez besoin de réponses en < 300ms et que votre prompt fait 3 000 tokens, le fine-tuning vous permet de comprimer ces instructions dans les poids du modèle et de réduire drastiquement la taille du contexte. Vous distillez un modèle plus grand Utiliser GPT-4o ou Claude Opus pour générer des milliers d'exemples de haute qualité, puis fine-tuner un modèle plus petit et moins coûteux. C'est la stratégie de distillation — légale, efficace, et de plus en plus commune.
Attention au dataset drift. Un modèle fine-tuné est figé dans le temps. Si votre domaine évolue (nouvelles réglementations, nouveau jargon, nouveaux produits), votre modèle dérive silencieusement. Prévoyez dès le départ un pipeline de ré-entraînement périodique — sinon le fine-tuning devient une dette technique.
Le vrai coût qu'on ne calcule pas
Avant de lancer un chantier de fine-tuning, estimez honnêtement :- Collecte des données : qui valide les exemples ? Combien d'heures d'expert métier ?
- Infrastructure d'évaluation : comment mesurez-vous que c'est mieux ? Un eval set rigoureux prend du temps.
- Maintenance : qui relance l'entraînement quand le modèle de base est mis à jour ?
- Versioning : comment gérez-vous les rollbacks si une version fine-tunée dégrade un edge case ?