Mercredi 3 juin 2026
Observabilité des LLMs en production : ce que vos dashboards ne vous montrent pas
Vous monitorez vos API avec Prometheus, vous tracez vos microservices avec Jaeger. Mais vos appels LLM ? Ils arrivent comme une boîte noire dans vos logs. Voici comment instrumenter sérieusement une application IA.
 Note sur le streaming : si vous servez des réponses en stream (SSE), la latence globale est une mauvaise métrique. Ce qui compte pour l'UX, c'est le time to first token — le délai avant que le premier caractère apparaisse à l'écran.
Note sur le streaming : si vous servez des réponses en stream (SSE), la latence globale est une mauvaise métrique. Ce qui compte pour l'UX, c'est le time to first token — le délai avant que le premier caractère apparaisse à l'écran.
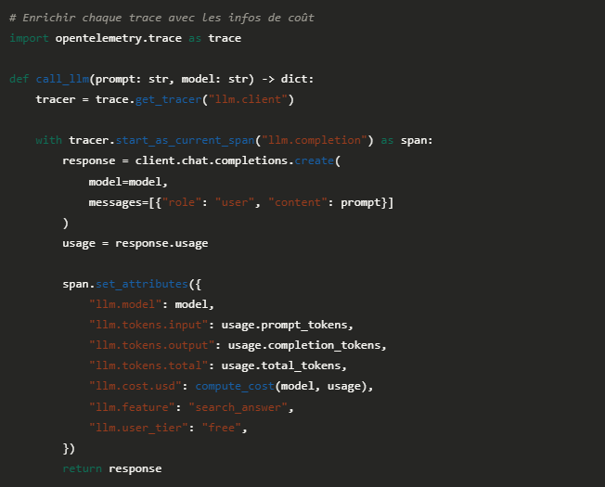 L'attribut llm.feature est souvent oublié. Sans lui, impossible de savoir si c'est votre feature de résumé ou votre chatbot qui explose votre budget.
L'attribut llm.feature est souvent oublié. Sans lui, impossible de savoir si c'est votre feature de résumé ou votre chatbot qui explose votre budget.
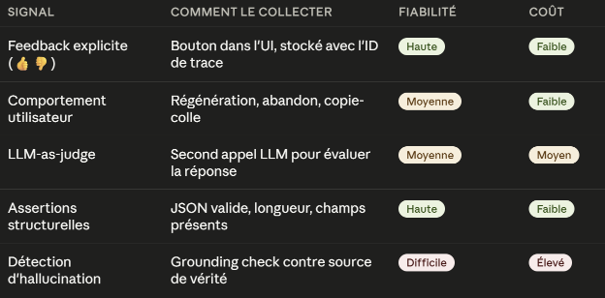 La stratégie pragmatique : commencer par les assertions structurelles et le feedback utilisateur. Le LLM-as-judge est puissant mais coûteux — réservez-le à l'évaluation offline ou aux cas critiques.
La stratégie pragmatique : commencer par les assertions structurelles et le feedback utilisateur. Le LLM-as-judge est puissant mais coûteux — réservez-le à l'évaluation offline ou aux cas critiques.
Le problème avec "ça marche, non ?"
Quand on demande à une équipe si son intégration LLM est monitorée, la réponse est souvent la même : "Oui, on a les temps de réponse et les codes HTTP." C'est comme dire qu'on monitore une base de données en regardant uniquement si les requêtes renvoient un 200. Un LLM peut répondre 200 OK en 800ms et produire une réponse complètement hors-sujet, halluciner un fait critique, ou dépenser 10× le budget token prévu. Aucun de ces problèmes n'apparaît dans vos métriques classiques. Le vrai contrat d'un LLM n'est pas technique, il est sémantique. Ce n'est pas "est-ce que l'API a répondu ?" mais "est-ce que la réponse était juste, utile, et dans les clous du business ?"Les 4 dimensions de l'observabilité LLM
1.La dimension opérationnelle (ce que vous avez déjà)
Latence, taux d'erreur, disponibilité — les métriques RED classiques. Elles restent indispensables, mais elles ne couvrent qu'une fraction du problème.
Note sur le streaming : si vous servez des réponses en stream (SSE), la latence globale est une mauvaise métrique. Ce qui compte pour l'UX, c'est le time to first token — le délai avant que le premier caractère apparaisse à l'écran.
2.La dimension économique (ce que vous regardez rarement)
Les tokens coûtent de l'argent. Mais le coût par requête varie d'un facteur 10 ou 20 selon comment vous construisez vos prompts. Sans visibilité fine sur la consommation, vous découvrez le dérapage sur la facture du mois suivant.
L'attribut llm.feature est souvent oublié. Sans lui, impossible de savoir si c'est votre feature de résumé ou votre chatbot qui explose votre budget.
3.La dimension qualité (ce qui est difficile à mesurer)
C'est là que ça devient intéressant — et complexe. Comment détecter automatiquement qu'une réponse est mauvaise ?
La stratégie pragmatique : commencer par les assertions structurelles et le feedback utilisateur. Le LLM-as-judge est puissant mais coûteux — réservez-le à l'évaluation offline ou aux cas critiques.
4.La dimension sécurité & dérive (ce qu'on oublie)
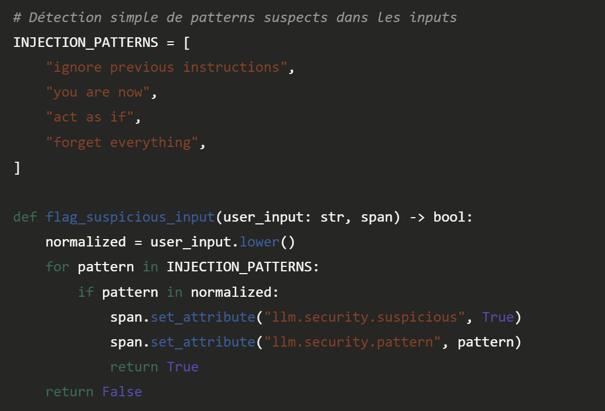
Les prompts de vos utilisateurs évoluent. Si vous ne les analysez pas dans le temps, vous raterez deux phénomènes dangereux :- Le prompt drift : la distribution des inputs change, et votre système prompt n'est plus adapté.
- Les tentatives d'injection : des patterns inhabituels qui tentent de contourner vos guardrails.